
Divide & Conquer Skeleton: Part One
Writing hand-rolled parallel software is difficult to do correctly. Using raw synchronisation primitives can be fiddly, and will likely introduce a whole host of runtime errors into your system. Most people do not recommended doing it. It’s difficult to make the mental switch from thinking in a serial system of execution (action A leads to action B which leads to action C) to thinking in a parallel system of execution.
One solution is to abstract the implementation of a parallel execution environment away from the problem. This is often the best approach as you can focus on the problem at hand rather than getting bogged down with race conditions and scheduling issues.
Patterns & Skeletons
One such abstraction method is the use of parallel patterns. Problems that can be parallelised often fall into common patterns. A very common parallel pattern is the divide and conquer pattern. The divide and conquer pattern works by dividing up tasks until they are small enough to process and then combines them back into one final result.
The divide and conquer pattern has four operations:
- A
dividefunction which splits a task into sub-tasks - A
combinefunction which takes several sub-tasks and combines them into one - A
basefunction which solves a task if it is small enough - A
thresholdfunction that determines whether to use the base or divide function
Any problem that can be framed in these 4 operations can be solved with the divide and conquer pattern.
Mergesort and quicksort are both examples of the divide and conquer pattern. An image of merge sort is shown below (taken from wikipedia). Here we can see what the four operations are:
Divide- split the list of numbers into two smaller lists of numbersCombine- merge two sorted lists into one larger sorted listBase- no-op (In this example do nothing as a list containing one number is sorted by definition)Threshold- is the length of the list one?
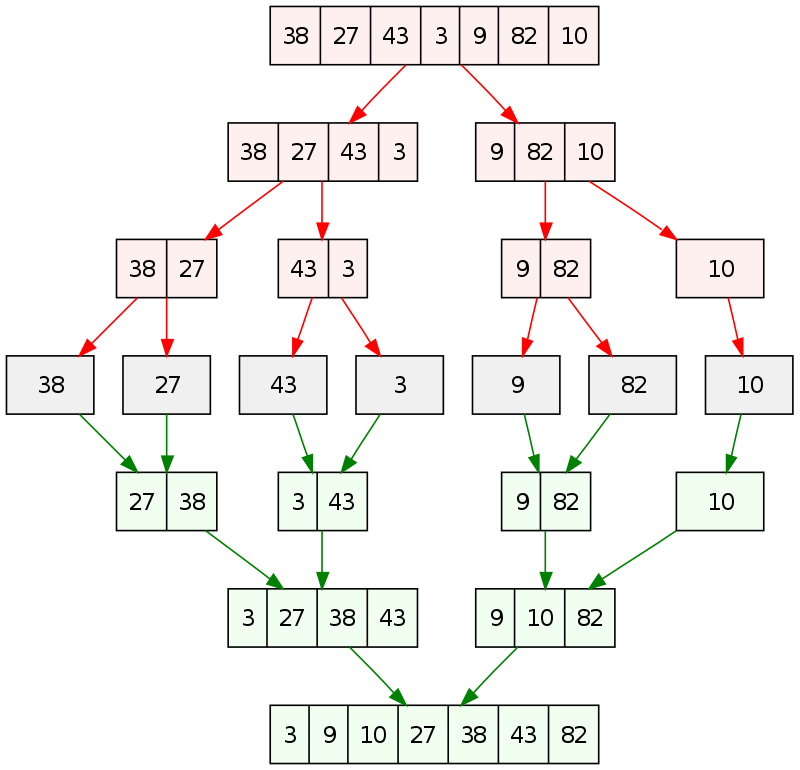
This graph is split into three phases. A divide phase, where all the tasks get created. A conquer phase, when the threshold for the base function is met and the tasks can be processed. A combine phase to eventuallly return the final result (a sorted list).
In all parallel patterns, a task represents a unit of work that can be performed independently. The patterns differ in how they generate and process a collection of tasks. Other patterns include the pipeline pattern, the worker pool pattern, and the task farm pattern.
A skeleton is an implementation of a pattern. A skeleton provides a parallel execution environment to solve the problem. A developer only has to provide the necessary operations of a pattern without worrying about locks, queues, race conditions, and hardware utilisation.
Divide & Conquer Skeleton
The skeleton developed in this project is an implementation of the divide and conquer parallel pattern. It works by being compiled with a header that defines four lambdas for each of the divide and conquer operations. For example, look at the mergesort header, it provides four lambdas which satisfy the four operations, similar to the operations described above. The header should also define a problem_t type and result_t type so that the skeleton knows what data types to operate on.
Work Sharing & Load Balancing
Under the hood, the skeleton can fully utilise the number of physical cores on the hardware that it is running on with work-sharing and load balancing schemes occurring. The skeleton spawns a worker thread for every available core on the hardware (P1,...,Pn). Each worker thread has its own thread-safe task queue (as seen in the image). Any, sub-tasks that are created by processing a task will be pushed back to the same worker thread task queue. Parent tasks that are waiting on sub tasks to complete are also pushed back to the same queue to ensure that sub-tasks will be processed before parent tasks.
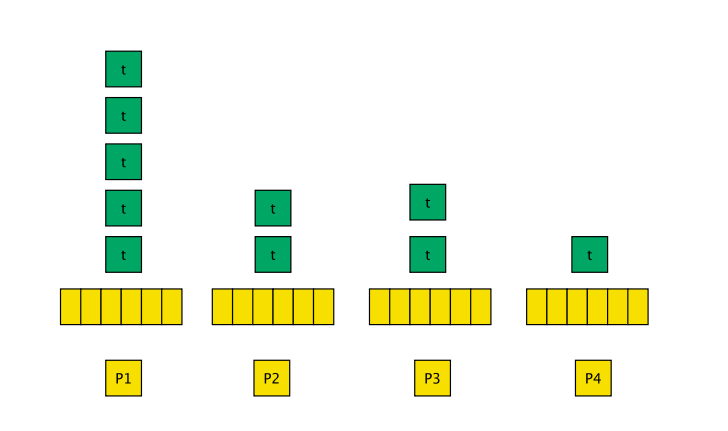
A worker thread will process all its own tasks until it has no more to process. At which point, a worker will try and steal a task from the queue of another worker. For example, P4 finishes its one task and steals from P1 which has many tasks. Tasks are only stolen from the front of the task queue to ensure sub-tasks are processed first. This load balancing scheme is aggressive but it ensures no core is over utilised.
Performance
For both mergesort and quicksort, an improvement in performance was made once the number of cores was 2+. This is good news but not great news. It shows that the proof of concept for the skeleton works but is probably not that efficient. What's most shocking is that on a single core it is almost twice as slow to use the skeleton that not at all. There is definitely improvements that can be made. Shown are the results for mergesort and you can see the rest of the results here.
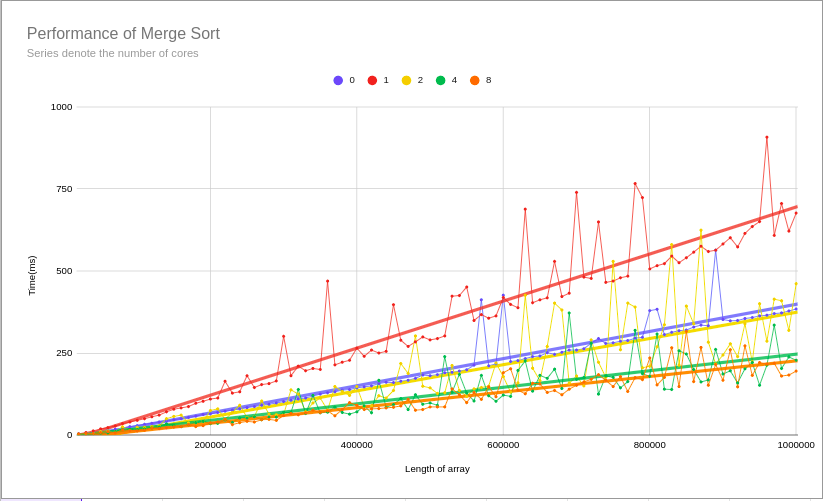
(Zero cores denotes the sequential execution benchmark)
Moving forward
There are a few things I would like to improve in this project. First, the multithreaded worker queue is a locking queue, implemented using a mutex. Locking queues and locking algorithms are notoriously slower than their lock-free counterparts. I have a lock-free queue that I want to incorporate into this project. Second, the worker class is fairly lightweight but the task class has 3 bools, 3 ints, a vector, a shared pointer, and more just to hold state. Given that for any task with a subtask only two bools may be read before the object never references again. It may be more cache-friendly to organise the data differently. Finally, the backend of this interface/skeleton is naively implemented in C++ but can it use existing infrastructure such as Intel TBB or OpenMP? How does each backend compare in performance?
Code
You can find the code for this project on my github.